The Yoga of Image Generation – Part 3
Raphaël Semeteys
- 5 Min To Read
- 24 Jun, 2025
In the first two parts of this series, we explored Stable Diffusion, ComfyUI, and how to build Text-to-Image and Image-to-Image workflows to generate images of Yoga poses. With the help of ControlNets, we learned how to transfer a pose from an abstract reference image to our final generated image.
See also:
A Yoga sequence consists of several connected poses, which means we need visual consistency across all generated images in the sequence. This consistency must first cover the style which we addressed in the previous part of the series but also the facial features of the person depicted.
LoRAs (Low-Rank Adapters)
Let’s now introduce a new component into our workflow to tackle this challenge: Low-Rank Adapters (LoRAs). LoRAs make slight adaptations to the base model they are trained on by modifying only a small subset of neural network parameters. This is a highly efficient technique, as it enables faster training, smaller file sizes, and lower memory usage. You can think of a LoRA as a patch applied at runtime to the base model. Multiple LoRAs can be chained together.

LoRAs are typically used to specialize an existing model with certain image features such as style, poses, concepts, or characters. They are triggered in prompts using specific keywords defined by the LoRA creator during training. The community offers numerous LoRAs available for download from sites like civitai.com, which can be integrated into your local ComfyUI workflows.
Here are two examples of images generated using a “Pencil drawing” LoRA, with two different keywords and all other parameters unchanged:

The community also offers countless LoRAs for generating images resembling celebrities. Let’s try using some of these to achieve facial consistency. We’ll start by testing Celebrity LoRAs with very light pose transfer (ControlNet strength set to 10%) to see how closely the generated faces match.

Promising results! Note that the poses aren’t identical across images, this is due to the low ControlNet strength we used.

Next, let’s incorporate these LoRAs into our previous pose generation workflow. I stacked two LoRAs: one for facial identity and another for a graphite drawing style. I also kept the two ControlNets we introduced earlier for pose transfer.

With this setup, we can generate sequences that are consistent in both style and facial identity.

Of course, we can change the celebrity reference or even chain multiple LoRAs together, adjusting their strengths to blend features of different identities. However, using public figures still feels a bit uncomfortable, potentially raising ethical concerns around deepfakes.
A better approach is to create your own LoRA, avoiding such issues. So I decided to train a LoRA using images of my wife. I first experimented with the DreamBooth method, using a Colab Notebook and Google GPUs. I trained the model on 28 images of her, using an SDXL base model, over 2 epochs, taking around 1.5 hours.
The results were… promising 😉 Here are some of the best images generated with my first custom LoRA:
")
The resemblance is there, but not quite enough, and the image quality was lacking. So I tried again, this time training the LoRA locally on my PC using the Kohya_ss open source tool. I selected the PowerPuffMix model (a fine-tuned of SDXL), trained on just 15 images but for 20 epochs. The process took about 3.5 hours and yielded better results.
")
This time, both image quality and facial identity were strong enough to integrate into our generation workflow.
Here are some outputs using the new LoRA. While the face doesn’t perfectly resemble my wife (likely due to the influence of ControlNets) the identity consistency we needed is clearly present.

The lighting is still a bit unstable, and overall image quality remains imperfect. I could improve this by training on more images and increasing the number of epochs. However, the final LoRA is still fundamentally linked to the base model and can’t be applied to another one.
Image Prompt Adapters (IP Adapters)
Let’s now try another technique: Image Prompt Adaptation, which is more decoupled from the base model. It functions similarly to a ControlNet but alters the model directly. Think of an IP Adapter as a one-image LoRA.
The FaceID IP Adapter, specialized in facial recognition and feature extraction, is a perfect fit for our needs.

While exploring facial enhancement tools, I also discovered FaceDetailer, which improves facial features (eyes, nose, lips, expression) after image generation. I decided to integrate both of these components into our workflow. FaceDetailer’s enhancements are based on the FaceID input, so they remain faithful to the original facial reference.
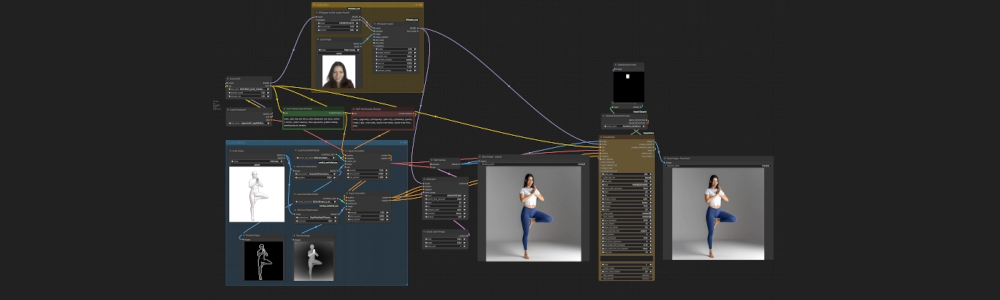
Here is the complete workflow:

We now finally achieve our desired outcome:
- Control over style via prompts and embeddings
- Control over pose via ControlNets
- Control over identity via the FaceID IP Adapter and FaceDetailer
This setup allows us to generate precise and coherent Yoga sequences.

Another advantage of this workflow is how easily we can switch the base model. For instance, here’s an example using the Cheyenne model, which specializes in cartoon and graphic novel styles:

It’s also incredibly easy to change the subject’s identity. Since FaceID only requires a single image and no training phase, here are examples generated with the exact same workflow, using my own face as input for facial identity:

This concludes our three-part series. My initial goal — generating accurate yoga poses and full sequences using only a local machine — has been achieved.
In Part 1 , we introduced Stable Diffusion and ComfyUI to build simple Text-to-Image workflows using prompts and embeddings. In Part 2 , we explored pose transfer using Image-to-Image workflows and ControlNets. In this final installment, we addressed facial consistency, first with LoRAs, then with the FaceID IP Adapter and the post-processing FaceDetailer.
You’re now ready to create custom workflows tailored to your specific visual goals. Enjoy experimenting with generative AI to express your creativity with precision!
Stay tuned for more image generation tutorials and in the meantime, feel free to explore my YouTube channel for more content.