
Devops on Google Cloud Platform: Automating your build delivery on GCP in nutshell
 Alexandre Touret
Alexandre Touret
 Vijayanand Premnath
Vijayanand Premnath- 8 Min To Read
- 25 Feb, 2025
Introduction
Nowadays IT projects tend to be complicated and gather many technologies. Building an app should then quickly become cumbersome.
Continuous Integration is therefore, more than ever, the cornerstone of every project. This article aims to present insights and feedback based on our experience and projects at Worldline. We will present how to build, ship applications on Google Cloud Platform using different technologies and practices. In addition, we will also highlight how AI could help us enhance the whole process on Google Cloud Platform.
Understanding CI/CD: A Key to Agile Software Development
In the fast-paced world of software development, the demand for quicker, higher-quality releases has never been greater. Continuous Integration and Continuous Delivery (or Continuous Deployment) have revolutionized the way teams approach software creation, making it faster, more efficient, and more reliable.
Continuous Integration (CI)
Continuous Integration is the practice that encourages developers to integrate their code changes into a shared repository frequently—often multiple times a day. Each integration is automatically verified through a series of builds and tests. The primary goal here is to identify issues early in the development process, enabling teams to resolve conflicts swiftly.
Continuous Delivery (CD)
Building on the principles of CI, Continuous Delivery ensures that the code integrated into the repository is always in a deployable state. With CD, automated processes facilitate the release of new updates, allowing teams to push software to production with minimal manual intervention. Continuous Deployment , a specific subset of this, automates the release of every code update that passes automated tests straight to production, making it instantly available to users.
How CI/CD Work Together
Think of CI/CD as a well-oiled machine—a pipeline that incorporates various stages:
- Code Commit: Developers make code changes and commit them to the repository.
- Build: The application is built automatically.
- Automated Testing: The new code is rigorously tested against a suite of automated tests.
- Staging Deployment: The build is deployed to a staging environment for further verification.
- Production Deployment: Upon passing all checks, the code can be deployed to production.
- This seamless integration of processes not only improves collaboration among development and operations teams but also increases the speed and reliability of software releases.
You probably understood CI/CD practices are not just buzzwords. They are essential tools that enable modern IT organizations to deliver software more efficiently and with greater quality.
The GCP application
In modern software development, automating DevOps pipelines is essential for maintaining agility, speed, and reliability. By leveraging the power of Google Cloud Platform (GCP) and integrating Artificial Intelligence (AI), you can further optimize your workflows for efficiency, resource management, and predictive analytics.
This article outlines how to automate a Continuous Integration and Continuous Deployment (CI/CD) pipeline for a Node.js backend and React frontend web application hosted on Google Kubernetes Engine (GKE). Additionally, we enhance the pipeline with AI-powered capabilities for predictive failure detection, automated issue resolution, and resource optimization.
Use Case: Automating Deployment for a Web Application
Our goal is to create an automated pipeline that builds, tests, and deploys Dockerized application artifacts to GKE upon code pushes.
Tools involved include:
- A GIT repository such as GitHub or GitLab : For hosting the source code.
- Cloud Build : For building and deploying code.
- Artifact Registry : To store Docker images.
- Google Kubernetes Engine (GKE) : For application hosting.
- Cloud Storage : For storing intermediate artifacts/logs.
- Cloud Pub/Sub (Optional) : For triggering advanced workflows.
- Cloud Monitoring and Logging : To monitor pipeline health.
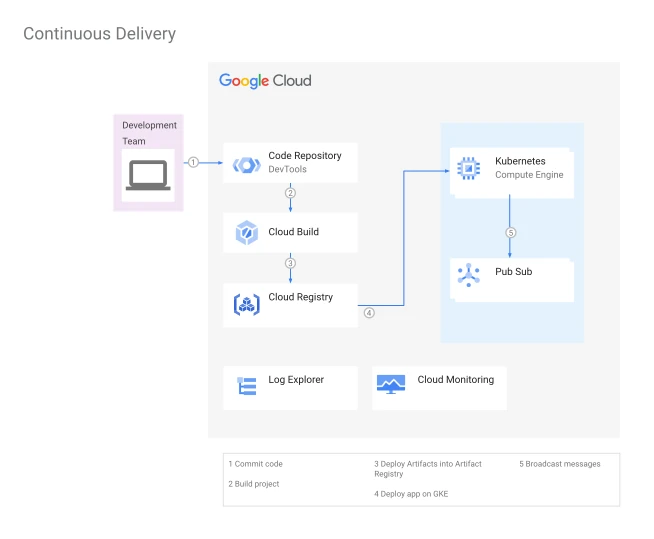
Step 1: Set Up GCP Project and Enable APIs
- Create a new GCP project:
gcloud projects create my-webapp-project --set-as-default
gcloud config set project my-webapp-project
- Enable necessary APIs:
gcloud services enable \
cloudbuild.googleapis.com \
container.googleapis.com \
artifactregistry.googleapis.com \
storage.googleapis.com \
monitoring.googleapis.com \
logging.googleapis.com
- Configure IAM roles: Assign roles for the service account used by Cloud Build and GKE.
gcloud projects add-iam-policy-binding my-webapp-project \
--member=serviceAccount:$(gcloud projects get-iam-policy my-webapp-project \
--flatten="bindings[].members" \
--filter="bindings.role:roles/cloudbuild.builds.builder" \
--format="value(bindings.members[0])") \
--role=roles/container.developer
Step 2: Connect GitHub to Cloud Build
- Link GitHub repository to GCP:
- Navigate to Cloud Build > Triggers in the GCP Console.
- Select Create Trigger and choose your repository.
- Define cloudbuild.yaml: Place the following file in your repository root to define the pipeline steps.
steps:
# Frontend build and Docker image creation
- name: 'gcr.io/cloud-builders/npm'
dir: 'frontend'
args: ['install']
- name: 'gcr.io/cloud-builders/docker'
dir: 'frontend'
args: ['build', '-t', 'us-central1-docker.pkg.dev/my-webapp-project/frontend:latest', '.']
# Backend build and Docker image creation
- name: 'gcr.io/cloud-builders/npm'
dir: 'backend'
args: ['install']
- name: 'gcr.io/cloud-builders/docker'
dir: 'backend'
args: ['build', '-t', 'us-central1-docker.pkg.dev/my-webapp-project/backend:latest', '.']
# Push images to Artifact Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'us-central1-docker.pkg.dev/my-webapp-project/frontend:latest']
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'us-central1-docker.pkg.dev/my-webapp-project/backend:latest']
# Deploy to GKE
- name: 'gcr.io/cloud-builders/kubectl'
args: ['apply', '-f', 'k8s/frontend-deployment.yaml']
- name: 'gcr.io/cloud-builders/kubectl'
args: ['apply', '-f', 'k8s/backend-deployment.yaml']
Step 3: Set Up Google Kubernetes Engine
- Create a GKE cluster:
gcloud container clusters create webapp-cluster \
--num-nodes=3 \
--region=us-central1
- Authenticate kubectl with GKE:
gcloud container clusters get-credentials webapp-cluster --region=us-central1
- Create Kubernetes manifests:
- Frontend Deployment (k8s/frontend-deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 3
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: us-central1-docker.pkg.dev/my-webapp-project/frontend:latest
ports:
- containerPort: 80
Step 4: Enable Continuous Deployment
With the cloudbuild.yaml file and Kubernetes manifests in place, code pushes to the GitHub repository will trigger the pipeline. Cloud Build will:
- Build Docker images for the frontend and backend.
- Push the images to Artifact Registry.
- Deploy the images to GKE using kubectl.
Step 5: Implement Rollback and Monitoring
- Enable Kubernetes health checks: Add liveness and readiness probes in Kubernetes manifests.
livenessProbe:
httpGet:
path: /health
port: 80
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 80
initialDelaySeconds: 10
periodSeconds: 5
- Rollback deployments manually (if necessary):
kubectl rollout undo deployment/frontend
kubectl rollout undo deployment/backend
- Enable monitoring: Use Cloud Monitoring and Logging for real-time insights into pipeline health.
Enhancing the Pipeline with AI
Enhancing the CI/CD pipeline for improved efficiency, reliability, and resource management. The AI system will focus on:
- Predictive Failure Detection: Analyzing logs and metrics to predict failures.
- Automated Issue Resolution: Automatically resolving common issues or recommending fixes.
- Resource Optimization: Dynamically allocating resources based on application workload.
Pipeline Enhancements
1. Predictive Failure Detection
Predict failures in the pipeline using historical data. This involves training a Machine Learning (ML) model to detect patterns leading to failures.
Data Collection:
Fetch logs and metrics from Google Cloud Monitoring and Logging.
from google.cloud import logging_v2, monitoring_v3
import pandas as pd
# Initialize clients
logging_client = logging_v2.Client()
monitoring_client = monitoring_v3.MetricServiceClient()
def fetch_logs():
logger = logging_client.logger('ci-cd-logs')
entries = logger.list_entries()
logs = []
for entry in entries:
logs.append(entry.payload)
return pd.DataFrame(logs, columns=["timestamp", "severity", "message"])
def fetch_metrics():
project_id = "projects/my-webapp-project"
query = f'projects/{project_id}/metrics'
results = monitoring_client.list_time_series(
request={"name": project_id, "filter": query, "interval": {"start_time": "...", "end_time": "..."}}
)
data = [{"timestamp": point.interval.end_time, "value": point.value.double_value} for ts in results for point in ts.points]
return pd.DataFrame(data)
Train an ML Model:
Use the collected data to train a classification model.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Prepare data
logs = fetch_logs()
metrics = fetch_metrics()
dataset = logs.merge(metrics, on="timestamp")
X = dataset.drop(columns=["severity"])
y = dataset["severity"] # Assume severity indicates failures
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Save model
import joblib
joblib.dump(model, "failure_detection_model.pkl")
Deploy Model in the Pipeline: Integrate the model into the pipeline to make real-time predictions.
import joblib
model = joblib.load("failure_detection_model.pkl")
def predict_failure(log_entry):
return model.predict([log_entry])
2.Automated Issue Resolution
Automate resolution of common issues based on detected patterns.
def resolve_issue(issue_type):
if issue_type == "build_failure":
print("Retrying build...")
# Trigger retry logic
elif issue_type == "deployment_failure":
print("Rolling back deployment...")
# Rollback logic
else:
print("Escalating issue to the team.")
3.Resource Optimization
Optimize resource allocation based on workload patterns.
from google.cloud import container_v1
def scale_resources(cluster_name, node_pool_name, project_id, region, desired_nodes):
client = container_v1.ClusterManagerClient()
cluster_path = f"projects/{project_id}/locations/{region}/clusters/{cluster_name}"
client.set_node_pool_size(
project_id=project_id,
zone=region,
cluster_id=cluster_name,
node_pool_id=node_pool_name,
node_count=desired_nodes
)
print(f"Scaled node pool {node_pool_name} to {desired_nodes} nodes.")
Use AI to predict required resources:
def predict_resources(logs, metrics):
# Simplified resource prediction logic
workload = metrics["value"].mean()
if workload > 80:
return 5 # High load
elif workload > 50:
return 3 # Medium load
else:
return 1 # Low load
Integrate this into the pipeline to dynamically adjust resources.
Complete Python AI Pipeline
Integrate all the above features into a Python script executed within the pipeline.
def main():
logs = fetch_logs()
metrics = fetch_metrics()
# Predict failure
for log in logs.itertuples():
if predict_failure(log):
issue_type = log.issue_type # Example field
resolve_issue(issue_type)
# Predict resources and scale
desired_nodes = predict_resources(logs, metrics)
scale_resources(
cluster_name="webapp-cluster",
node_pool_name="default-pool",
project_id="my-webapp-project",
region="us-central1",
desired_nodes=desired_nodes,
)
if __name__ == "__main__":
main()
Monitoring and Alerts
Use Google Cloud Monitoring to trigger alerts based on ML predictions or unexpected behavior.
Configure alert policies in the GCP console. Use Python to send notifications via Pub/Sub or email when anomalies are detected.
from google.cloud import pubsub_v1
def send_alert(message):
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path("my-webapp-project", "alerts")
publisher.publish(topic_path, message.encode("utf-8"))
Conclusion
We saw in this article how to easily automate the deployment process for a web application using Google Cloud tools like Cloud Build, Artifact Registry, and Google Kubernetes Engine. This setup streamlines the CI/CD pipeline, ensuring faster and more reliable deployments.
With the integration of GitHub or GitLab, any code push automatically triggers the build, test, and deployment process, keeping your application up-to-date. Adding health checks and monitoring improves the robustness of your system, while rollback mechanisms provide a safety net for deployments.
Last but not least, enhancing the pipeline with predictive AI models can further optimize workflows by identifying potential failures before they occur. This approach demonstrates the power of combining DevOps best practices with cutting-edge AI tools to create a resilient and scalable deployment pipeline.