
Under the Hood: Understanding Java Volatiles
 Gilles Roux
Gilles Roux- 14 Min To Read
- 31 Jul, 2024
Introduction
Upon revisiting the keyword volatile while scrutinizing a codebase, and deeply pondering its necessity and the underlying mechanisms, I realized that perhaps I hadn’t fully grasped its function. I understood that it was intended to address the synchronization issues of updating shared variables across multiple concurrent threads, yet I couldn’t summon a comprehensive overview of the techniques involved, from the inner workings of the JVM (Java Virtual Machine) to the computer’s memory.
Disturbed by my ignorance, I turned to my colleagues, inquiring about what this volatile actually did and how it did it. To my surprise, none could provide a pertinent vision of the matter, even without delving into secondary details, despite their practices guiding them towards the correct use of this keyword. Concurrent programming often proves to be a delicate affair, necessitating an in-depth technical mastery if one aims to produce code that, first, works, and second, is maintainable and performant. This topic, I realized, was a quintessential technical trap, where only a sound understanding of the mechanisms at play allows for the proper structuring of code in concurrent programming.
I did not anticipate that this volatile would lead me so far and so deep. Seemingly innocuous, it conceals an iceberg of delights for those who relish questioning.
The problem(s)
Concurrent programming presents numerous design challenges. Firstly, it’s essential to establish principles of healthy collaboration and competition among different processes working on shared objects. Secondly, it’s crucial to optimize the execution of this complex assembly on the microprocessor architectures at our disposal.
We won’t tackle all these challenges within the confines of this limited article; instead, we’ll focus on a simple case to illustrate the necessity—or at least the interest—of the volatile principle.
Single-Threaded Execution
Let’s consider a set of variables that need to be updated with new values. These variables are shared due to their definition as static:
static int static_valueA=0, static_valueB=0;
static boolean static_newValuesFlag=false;
A final variable, static_newValuesFlag, will contain a flag to indicate that the set is up-to-date and ready for use. Here’s a simple code snippet corresponding to this update procedure:
(1) static void setValues(int arg_valueA, int arg_valueB) {
static_valueA=arg_valueA;
static_valueB=arg_valueB;
static_newValuesFlag=true;
}
Next, another method will be responsible for utilizing this update if it has occurred:
(2) static void printNewValues() {
int a,b;
if(static_newValuesFlag) {
a=static_valueA;
b=static_valueB;
System.out.println("New values detected: A="+a+",New B="+b);
}
}
Since we’re executing the code on a single thread, the methods execute sequentially without interruption. During the execution of (2), if (1) was executed beforehand, the detection of the static_newValuesFlag ensures that the newly modified values will indeed be loaded, resulting in:
Calling setValues(6,8) and printNewValues() sequentially...
New values detected: A=6, B=8
Multi-Threaded Execution
Now, let’s consider the same code executed in two threads running concurrently, without any synchronization mechanism to regulate their execution. At first glance, we might not expect the behavior to differ. Yet, there’s a possibility that the displayed result could be:
Calling setValues(6,8) and printNewValues() in 2 separate threads...
New values detected: A=0, B=0
And this is where we need to pause to understand what this signifies!
In (1), we have a sequence updating the variables, finishing with setting static_newValuesFlag. If this order was respected, there’s no way we could find ourselves in a situation where static_ newValuesFlag == true while static_valueA or static_valueB remain at 0.
The execution of the Java program thus hides behavior that doesn’t correspond to what’s written—a reality that may initially seem infuriating. But why on earth is this happening?!
The Magic of Compilers and Optimizations
Execution of a Java Program
To get things perfectly clear, let’s first situate ourselves in the chain that prepares and executes a program. We have:
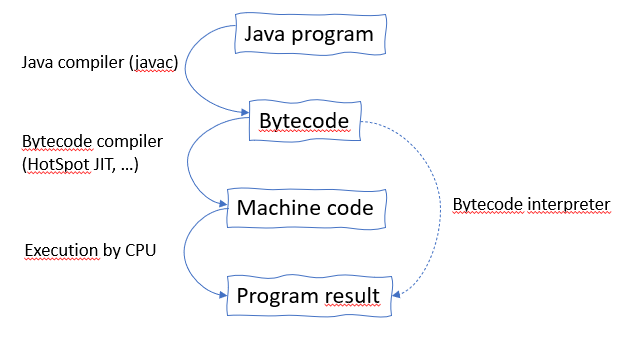
- Java Source Code: The only code the programmer is supposed to inspect.
- Java Compiler -> Bytecode: Takes the Java source to produce bytecode.
- Bytecode: A technical low-level version of the program ready to be executed by a virtual machine. Bytecode is CPU architecture-independent.
- Bytecode Compilation: The JVM produces final, executable machine code using one or several bytecode-to-machine language compiler.
- Machine Code: The final version of the program that is actually executed by the CPU.
- Execution of Machine Code by the CPU.
- Result.
Alternatively, the JVM, in a non-optimized mode, can also execute bytecode directly by interpreting it on the fly.
Let’s add that bytecode compilation can be performed by several compilation mechanisms. It can be done beforehand or during runtime when the JVM deems it appropriate. In the latter case, several compilers may kick in, each with different optimization and performance goals (C1 and C2 compilers).
Where the Problem Lies
The issue described earlier is actually generated at the level of bytecode execution. We hypothesized that the program being executed did not correspond to the sequence of instructions in the source code.
Well, let’s imagine the Java code had been written differently, by changing the order of the instructions of (1), like so:
static_newValuesFlag=true;
static_valueA=arg_valueA;
static_valueB=arg_valueB;
What would be the impact on single-threaded execution? None whatsoever, since the code fragments are executed without interruption, and the swapped lines do not interfere with each other.
In a multi-threaded execution scenario, however, we might find ourselves with instructions unfolding in the following sequence:

The result of such execution would then be:
New values detected: A=0, B=0
It’s not immediately clear why such a reorganization of the program’s execution order would occur in this example. In fact, it’s important to note that, in practice, it might not happen at all; if you try running code similar to this example, you’ll likely get a program that works correctly.
What you need to keep in mind is that the possibility exists, and the compiler has the right to reschedule a sequence of instructions, as long as this restructuring yields an identical result in single-threaded execution.
Optimizations Galore
So, we’re saying that the compiler is free to rearrange the order of operations relative to what the source code might imply. This sort of flexibility contributes to potential optimizations, but there are more to consider.
Take, for instance, the following code, which aims to wait for a stop signal:
boolean mustStop = 0;
...
while (!mustStop) {
wait();
}
stop();
For the program to stop, the boolean mustStop needs to be set, and this variable must reload to exit the while loop. In a single-threaded execution, this code obviously makes no sense, as there’s no one to modify the variable. In a multi-threaded execution, we rely on another thread to signal the stop, but this code is likely to produce surprising results.
Given that the compiler is free to assume that the code it generates simply needs to be correct in a single-threaded context, it’s possible that at runtime, the variable mustStop is only read once from memory. Nothing in this code suggests it will be changed. Based on similar test cases I’ve seen, the result is indeed very random, depending on interpretation or compilation conditions.
When a code fragment manipulates a variable intensely, such as in heavy calculations, it’s impractical to keep reading it from memory each time. If the compiler deems it unnecessary, having analyzed that the variable can’t change, it will generate machine code that reads the variable once to store it in an intermediate register, thereby achieving far superior performance through register manipulation.
The advancement of compiler technology today enables absolutely brilliant optimizations, derived from numerous principles of different kinds. Some stem from functional analysis, others from efficiency considerations within the JVM architecture, or even at a very low level to ensure the generated machine code performs well on certain CPU architectures.
One can’t predict or foresee if a compiler will deeply rework the implementation of the source instruction sequence. But it’s a safe bet that it will, unless instructed otherwise.
Let’s Convince Ourselves with Real Generated Machine Code
A lot of words so far, but let’s see how this translates to low-level code in the generated output. As before, we’re dealing with shared static variables in very simple operations. This may not constitute a grand demonstration, but it keeps our analysis tightly controlled—otherwise, things can quickly get unwieldy.
Here’s the source code for Formul.java:
class Formul {
static int static_valueA=0;
static int static_valueB=0;
static int static_valueC=0;
static boolean static_newValuesFlag=false;
static void setValues(int arg_valueA) {
static_valueA=123456/(static_valueB%arg_valueA)+static_valueC;
static_valueB=123456/(static_valueB%arg_valueA)+static_valueC;
static_newValuesFlag=true;
}
static void printNewValues() {
int a,b;
if(static_newValuesFlag) {
a=static_valueA;
b=static_valueB;
System.out.println("New A="+a+",New B="+b);
}
}
public static void main(String[] args) {
Formul.setValues(Integer.valueOf(args[1]));
Formul.setValues(1);
Formul.setValues(6);
Formul.printNewValues();
}
}
This little code snippet has no practical use, just illustrative. We’ll focus on the setValues() method, first examining the bytecode generated by the Java compiler (Formul.class produced by javac Formul.java). Using the JDK’s .class file disassembler allows us, among other things, to observe the bytecode of methods:
javap -l -c -s -v Formul
A lot of information about the .class is displayed; let’s look at the disassembled bytecode of setValues():
public static void setValues(int);
descriptor: (I)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=1, args_size=1
0: ldc #7 // int 123456
2: getstatic #8 // Field static_valueB:I
5: iload_0
6: irem
7: idiv
8: getstatic #14 // Field static_valueC:I
11: iadd
12: putstatic #17 // Field static_valueA:I
15: ldc #7 // int 123456
17: getstatic #8 // Field static_valueB:I
20: iload_0
21: irem
22: idiv
23: getstatic #14 // Field static_valueC:I
26: iadd
27: putstatic #8 // Field static_valueB:I
30: iconst_1
31: putstatic #20 // Field static_newValuesFlag:Z
34: return
Even without being fluent in bytecode, the implemented logic is quite clear. The scalar 123456 is loaded (line 0:), divided (line 7:) by static_valueB modulo arg_valueA (line 6:), then static_valueC is added (line 11:), and the result is stored in static_valueA (line 12:). The exact same calculation is then stored in static_valueB (line 27:).
So far, no special optimization or transformation is detected.
The moment everyone has been eagerly awaiting has arrived; let’s examine the machine code produced by the compiler. Note that from this point on, we delve into the internal workings of a specific JVM, namely OpenJDK 17. Convenient runtime options in OpenJDK provide us with the information we seek:
- -Xcomp: Forces the JVM to compile all classes before their first execution, ensuring we get compiled code, independent of the whims of the JIT compiler.
- -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly: These options instruct the JVM to output all the compiled code to the standard output.
Beware, OpenJDK is not capable by default of displaying the disassembled code version unless you couple it with the hsdis plugin specific to the underlying CPU architecture (e.g., hsdis-amd64.so).
The result fills you with joy: 1,000,000 lines of disassembly. Rhââ lovely!
Let’s say you manage to find the fragment you’re interested in amidst all that (not an easy task, especially with tricks like inlining), you might see something like this:
1 0x00007f2d39104623: mov 0x74(%rdi),%eax ;\*getstatic static_valueB {reexecute=0 rethrow=0 return_oop=0}
2 0x00007f2d39104626: cmp $0x80000000,%eax
3 0x00007f2d3910462c: jne 0x00007f2d3910463d
4 0x00007f2d39104632: xor %edx,%edx
5 0x00007f2d39104634: cmp $0xffffffff,%esi
6 0x00007f2d39104637: je 0x00007f2d39104640
7 0x00007f2d3910463d: cltd
8 0x00007f2d3910463e: idiv %esi ; implicit exception: dispatches to 0x00007f2d3910480d
9 0x00007f2d39104640: mov %rdx,%rsi ;*irem {reexecute=0 rethrow=0 return_oop=0}
10 0x00007f2d39104643: mov $0x1e240,%eax
11 0x00007f2d39104648: cmp $0x80000000,%eax
12 0x00007f2d3910464e: jne 0x00007f2d3910465f
13 0x00007f2d39104654: xor %edx,%edx
14 0x00007f2d39104656: cmp $0xffffffff,%esi
15 0x00007f2d39104659: je 0x00007f2d39104662
16 0x00007f2d3910465f: cltd
17 0x00007f2d39104660: idiv %esi ; implicit exception: dispatches to 0x00007f2d39104812
18 ;*idiv {reexecute=0 rethrow=0 return_oop=0}
19 0x00007f2d39104662: mov 0x78(%rdi),%esi ;*getstatic static_valueC {reexecute=0 rethrow=0 return_oop=0}
20 0x00007f2d39104665: add %esi,%eax
21 0x00007f2d39104667: mov %eax,0x70(%rdi) ;*putstatic static_valueA {reexecute=0 rethrow=0 return_oop=0}
22 0x00007f2d3910466a: mov %eax,0x74(%rdi) ;*putstatic static_valueB {reexecute=0 rethrow=0 return_oop=0}
23 0x00007f2d3910466d: movb $0x1,0x7c(%rdi) ;*putstatic static_newValuesFlag {reexecute=0 rethrow=0 return_oop=0}
We find in the machine code what was expressed in the bytecode. Let’s first locate the addresses of our static variables in this context:
static_valueA : 0x70(%rdi)
static_valueB : 0x74(%rdi)
static_valueC : 0x78(%rdi)
static_newValuesFlag : 0x7c(%rdi)
Next, we can fairly easily read the calculation sequence:
- the modulo (line 8)
- loading the 123456 scalar (line 10)
- the division (line 17)
- the addition (line 20)
But then the code diverges from what the bytecode expresses, because the result of the calculation is assigned to both static_valueA and static_valueB (lines 21 and 22)!
We have discovered a blatant optimization performed by the bytecode compiler. This was done because, as we saw earlier, it was unnecessary to reapply the calculation line, whose result would necessarily be identical in a single-threaded context. It makes perfect sense to reuse data still present in the registers.
Volatiles to the Rescue
The volatile keyword allows us to indicate that a variable is likely to have its content changed at any moment because it might have been modified unpredictably by some thread within the JVM. The compiler must act accordingly by generating code that always ensures the current value of the variable is used.
Let’s observe this in our example by examining the machine code generated after declaring our static variables as volatile:
static volatile int static_valueA;
static volatile int static_valueB;
static volatile int static_valueC;
static volatile boolean static_newValuesFlag;
1...
20x00007fef15104623: mov 0x74(%rdi),%eax ;*getstatic static_valueB {reexecute=0 rethrow=0 return_oop=0}
30x00007fef15104626: cmp $0x80000000,%eax
40x00007fef1510462c: jne 0x00007fef1510463d
50x00007fef15104632: xor %edx,%edx
60x00007fef15104634: cmp $0xffffffff,%esi
70x00007fef15104637: je 0x00007fef15104640
80x00007fef1510463d: cltd
90x00007fef1510463e: idiv %esi ; implicit exception: dispatches to 0x00007fef1510492d
100x00007fef15104640: mov %rdx,%rbx ;*irem {reexecute=0 rethrow=0 return_oop=0}
110x00007fef15104643: mov $0x1e240,%eax
120x00007fef15104648: cmp $0x80000000,%eax
130x00007fef1510464e: jne 0x00007fef1510465f
140x00007fef15104654: xor %edx,%edx
150x00007fef15104656: cmp $0xffffffff,%ebx
160x00007fef15104659: je 0x00007fef15104662
170x00007fef1510465f: cltd
180x00007fef15104660: idiv %ebx ; implicit exception: dispatches to 0x00007fef15104932
19 ;*idiv {reexecute=0 rethrow=0 return_oop=0}
200x00007fef15104662: mov 0x78(%rdi),%edx ;*getstatic static_valueC {reexecute=0 rethrow=0 return_oop=0}
210x00007fef15104665: add %edx,%eax
220x00007fef15104667: mov %eax,0x70(%rdi)
230x00007fef1510466a: lock addl $0x0,-0x40(%rsp) ;*putstatic static_valueA {reexecute=0 rethrow=0 return_oop=0}
240x00007fef15104670: mov 0x74(%rdi),%eax ;*getstatic static_valueB {reexecute=0 rethrow=0 return_oop=0}
250x00007fef15104673: cmp $0x80000000,%eax
260x00007fef15104679: jne 0x00007fef1510468a
270x00007fef1510467f: xor %edx,%edx
280x00007fef15104681: cmp $0xffffffff,%esi
290x00007fef15104684: je 0x00007fef1510468d
300x00007fef1510468a: cltd
310x00007fef1510468b: idiv %esi ; implicit exception: dispatches to 0x00007fef15104937
320x00007fef1510468d: mov %rdx,%rsi ;*irem {reexecute=0 rethrow=0 return_oop=0}
330x00007fef15104690: mov $0x1e240,%eax
340x00007fef15104695: cmp $0x80000000,%eax
350x00007fef1510469b: jne 0x00007fef151046ac
360x00007fef151046a1: xor %edx,%edx
370x00007fef151046a3: cmp $0xffffffff,%esi
380x00007fef151046a6: je 0x00007fef151046af
390x00007fef151046ac: cltd
400x00007fef151046ad: idiv %esi ; implicit exception: dispatches to 0x00007fef1510493c
41 ;*idiv {reexecute=0 rethrow=0 return_oop=0}
420x00007fef151046af: mov 0x78(%rdi),%edx ;*getstatic static_valueC {reexecute=0 rethrow=0 return_oop=0}
430x00007fef151046b2: add %edx,%eax
440x00007fef151046b4: mov %eax,0x74(%rdi)
450x00007fef151046b7: lock addl $0x0,-0x40(%rsp) ;*putstatic static_valueB {reexecute=0 rethrow=0 return_oop=0}
460x00007fef151046bd: mov $0x1,%eax
470x00007fef151046c2: mov %al,0x7c(%rdi)
480x00007fef151046c5: lock addl $0x0,-0x40(%rsp) ;*putstatic static_newValuesFlag {reexecute=0 rethrow=0 return_oop=0}
49...
We notice that the optimization analyzed earlier has disappeared. Now, the formula is indeed evaluated twice. It is now explicit to the compiler that the variables are shared and may be modified at any moment, even between the two calculations.
The optimizations we discussed earlier cannot be applied when the volatile keyword is attached to variables. Operations will no longer be reordered, and variables will always be read directly from memory without benefiting from register storage. Needless to say, the performance of certain algorithms is significantly impacted.
And that’s not the end of it; the CPU is a key player too
If it were only about Java considerations, it would be too easy! Earlier, we mentioned that a program might behave as if the memory writes of variables were not performed in the same order expressed by the source code. Well, such behaviors can also stem from low-level mechanisms within the CPU itself.
If our modern processors are so much more powerful compared to those from 20 years ago, despite having the same clock frequency, it is particularly due to on-the-fly execution optimizations that sometimes rearrange and parallelize the scheduling of machine instructions.
The topic is exceedingly complex, so let’s keep it simple.
When writing a volatile variable, the JVM (OpenJDK-amd64, as each CPU architecture may have its own specifics) triggers an additional instruction, as seen in the example above:
lock addl $0x0,-0x40(%rsp)
This is an addition of the value 0, which seems pointless. But note the lock prefix, whose consequence will be the synchronization of writes. This is called a write-barrier.
And What About CPU Caches?
CPU caches are frequently blamed for the more or less local states of variable updates. If, like me, you quickly research how to work with shared data, you’ll probably come across one of the countless sources explaining that these various caches potentially expose different values for the same memory address, depending on where a thread is executed, and this is due to non-instantaneous synchronization of values between caches and memory.
On the most common architectures, here’s a very simplified representation of the cache architecture:
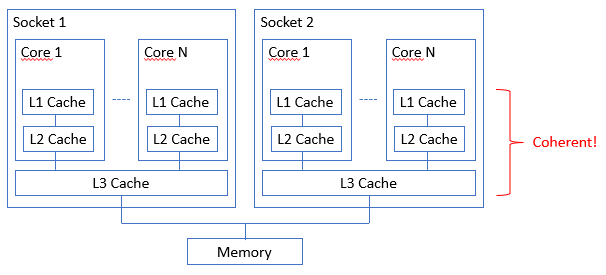
A memory datum can therefore be replicated in a large number of caches of various sizes and performances, but… Don’t let this architecture intimidate you!
In reality, your CPU architecture ensures cache coherence so that all cores have a consistent view of a memory value at any given moment, sharing the same view of state changes over time. Even in multi-CPU, multi-socket systems, caches are coherent between/across sockets.
The realm of cache management is a marvelous world, with numerous strategies and algorithms (MESI , for instance), and I encourage you to dive into it. Understanding them helps design performant programs (because modifying shared variables can sometimes ruin the benefit of caches). But this is another adventure; for now, rest assured that volatile is not about protecting against dysfunctional cache coherence!
Final Word
This article simply aims to give you a glimpse into the mechanics behind the enigmatic volatile, as I believe this is the kind of topic where lifting the hood is beneficial for proper understanding.
I hope this has raised your awareness and will help you avoid pitfalls by fostering the right mindset during design.
The worst pitfall, I believe, is that a program lacking volatiles can work splendidly, until one day it starts exhibiting strange and random behaviors due to a slightly different compilation, a JVM change, or a shift in architecture, exposing it to the whims of uncontrolled concurrency.
Of course, we have barely scratched the surface of the many challenges in concurrent programming.
Links
- The Java Memory Model : Read the Chapter 17 of the Java specifications and discussions about it.
- Myths about CPU Caches