
Metric-Driven Development of a RAG system
 Luxin Zhang
Luxin Zhang- 14 Min To Read
- 12 Jan, 2024
Prerequisites
- Basic knowledge of pros and cons of LLM APIs
- Preliminary knowledge of RAG structure
Introduction
Retrieval Augmented Generation (RAG) is commonly used to enhance the performance of LLM-based systems or incorporate domain-specific knowledge to improve the generated answers of the LLM. However, effectively evaluating and tracking the performance of a RAG system is not straightforward, posing a real challenge in the development and monitoring of such systems in a production environment.
Some open-source packages and commercial products, such as RAGAS and Deepchecks , have provided solutions to this problem. After exploring existing solutions, this article aims to recommend metrics for your RAG system and offer insights on interpreting these metrics. At the end of this article, we will also share our user experience with RAGAS and Deepchecks. 😉
Metrics
A RAG system often consists of two stages. The Information Retrieval (IR) stage aims to collect relevant documents, the so-called context, from a vector base to answer the user’s query, and a generation stage using prompt and LLM to reformulate a response based on the IR context. To precisely evaluate the performance of such a system and identify the RAG pipeline’s bottlenecks, every stage should be evaluated separately as well as the whole pipeline. Based on our experience, we have identified the following 5 essential metrics (categorized in 3 groups):
IR Metrics
- Recall of the IR: Whether the retrieved context contains sufficient information.
- Precision of the IR: Whether the retrieved context is redundant or noisy.
LLM Metrics
- Faithfulness of the generated response compared to the retrieved context: Whether the response is generated based on the retrieved context.
RAG Pipeline Metrics
- Completeness of the generated response compared to the ground truth answer: Whether the generated response covers all points.
- Relevance of the generated response compared to the user’s query: Whether the generated response is relevant to the user’s query.
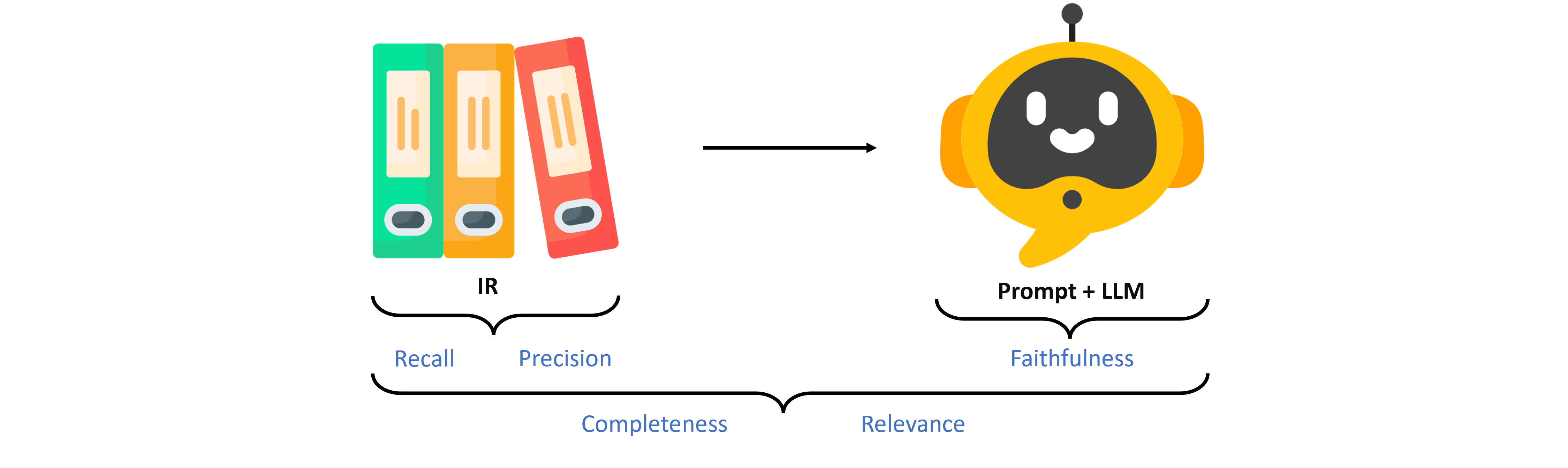
Besides, it is also worth to consider toxicity measurement and some languistic metrics. In this article, we solely focus on the 5 metrics mentioned above to mesure how ‘accure’ the generated response is.
Dataset
It is often necessary to prepare a “golden dataset” to compute these quality metrics, including the following information:
- The user’s query
- The ground truth answer
- The retrieved context
- The generated response
The user’s query and ground truth answer are often shared between different versions of the same RAG system, while the retrieved context and generated response are specific to each version and modification of the RAG pipeline.
The construction of such a dataset depends highly on one’s specific use case, especially for the query and ground truth. The dataset collection can be based on an existing system, in a demo, or through internal collaborations. There is no optimal way for this dataset collection. However, we can provide some intuitions on diverse questions that are nice to include.
High-frequency questions: It is evident that the first questions to include should be the most frequent ones. This can ensure the response’s correctness for the most common situations. To increase query diversity, one can ask LLM to generate some alternative queries that have the same semantic meaning as the original one but are formulated differently.
Context-sensitive questions: We have noticed that given the ground truth context, most of the user’s questions can be answered correctly. However, some queries are more sensitive to the noise in the context than others. To automatically construct a context-sensitive question dataset, one can first use a self-instruct schema to generate synthetic questions from given contexts and ask LLM to respond to them. Then, adding noise to the contexts and have LLM regenerate a response. The questions that have different responses between the two versions are considered as context-sensitive. We also find that using code snippets and URL links as noise is more likely to deteriorate the generated response of the LLM, thus helping to identify those context-sensitive questions.
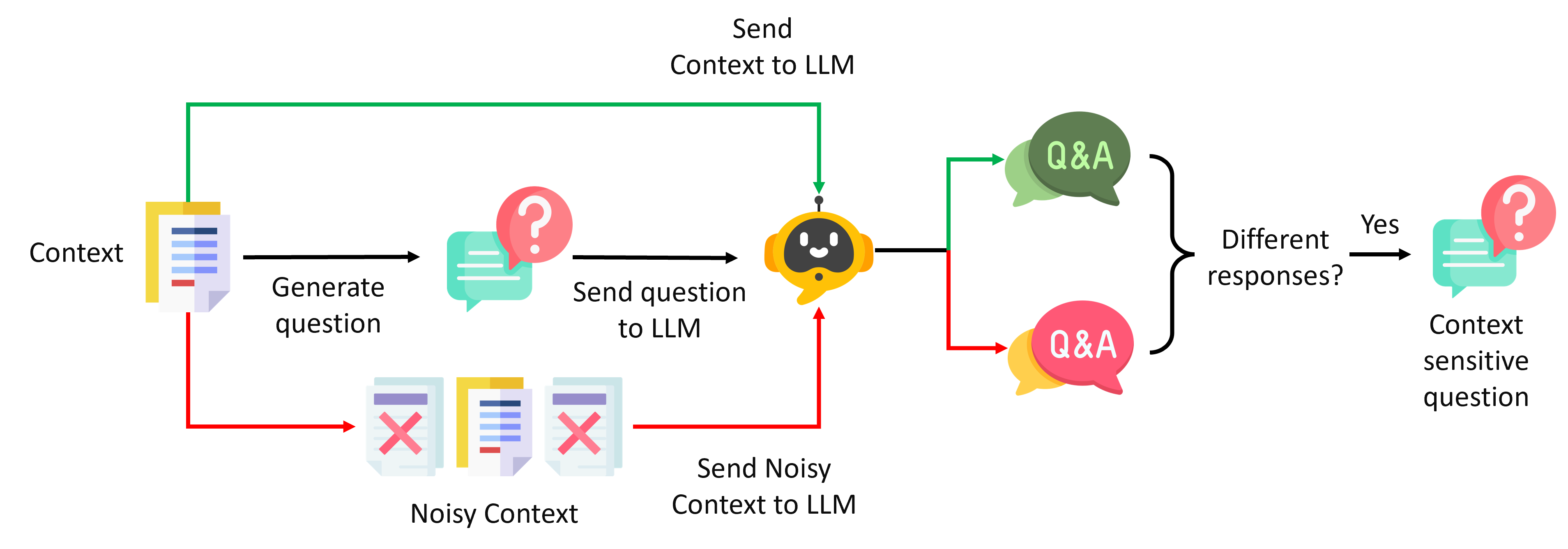
Multi-language Questions: These questions can help check if the system works when the user’s query is not in the same language as the context and test whether the LLM output respects the language that one has set. Moreover, even in the use case of a single language, asking the same question in a different language can help check the consistency of a RAG system.
Outlier Questions: Outlier questions are those that do not have relevant or precise context in the database and should be answered with “sorry, I do not have enough information to answer your question” or something similar. The objective of this dataset is to check if the RAG pipeline outputs hallucinations based on its prior knowledge. An example can be like:
{
"Context": "The Car Insurance from THEBESTINSURANCE is an auto insurance policy with 3 packages, additional options, and essential coverages to meet the specific needs of every driver."
"Question": "What are the 3 car insurance packages proposed by THEBESTINSURANCE?"
"Ground truth answer": "Sorry, the 3 car insurance packages offered by THEBESTINSURANCE are not detailed on the site. Please contact the customer service for more information."
"Hallucination answer": "The three car insurance plans offered by THEBESTINSURANCE are as follows: Basic Plan: This plan provides essential coverage to meet the specific needs of each driver. Intermediate Plan: In addition to the coverage provided by the basic plan, this plan offers additional options for personalized protection of your vehicle. Comprehensive Plan: This plan provides maximum protection by including all the coverage of the intermediate plan, along with additional options for extended coverage.
}
In the given example, the user’s question is actually a trap, as the context does not contain information about the 3 packages. One would expect the LLM to admit that it does not have enough information to answer the question. However, the hallucinated answer invents some plans based on the LLM’s prior knowledge.
Number-related questions. Code-related questions… It is desirable to adapt the question set to one’s specific use case. Number-related questions and code-related questions are two examples that often appear. Different from classical questions that look for a semantic match, number-related and code-related questions, such as those asking for solutions to a specific error code, sometimes require an exact match of the context. Including these questions helps to check if the RAG pipeline covers different information retrieval and generation strategies. It is also worth asking the LLM to count something, like the number of services provided by a company, to check if the LLM can handle number-related questions.
Of course, there are many other questions that can be included in the question dataset. Don’t hesitate to share your experience with us if you have any other ideas!
Insights on Metrics
Let’s now cross-match the metrics with the dataset we have prepared and see how different metrics are computed and what insights they can provide. To understand the metrics in more granularity, we use a similar approach as RAGAS by decomposing contexts and answers into sets of statements. We denote separately the sets of statements of the context, the ground truth answer, and the generated response as $C$, $G$, and $R$. The following mathematical definitions are indicative, and different implementations have their adapted formulas.
Recall of IR.
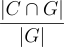
The recall metric is computed based on the IR context and the ground truth answer, indicating if the extracted context has sufficient information (covers all statements) to answer the question or not. This metric can be considered as the “upper bound” of the global RAG pipeline quality. Several options can be applied to try to increase this score, such as using a better embedding module or changing the document searching strategy (using a cross-encoder, for example).
Precision of IR.
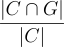
Similar to recall, precision is computed based on the same text but with a different denominator. It measures the percentage of contexts that are relevant to the ground truth answer. In common cases, precision decreases when one includes more context. Unlike recall of IR, which indicates the upper bound of the RAG system quality, a low precision score does not necessarily mean a poor quality of the whole system. However, a low precision often means there is too much irrelevant text in the prompt, thus making it more expensive to use an LLM API. Moreover, it can also encourage LLM to generate question-irrelevant responses.
Faithfulness.
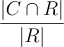
Faithfulness compares the context with the generated response, testing whether the response is generated based on the given context, and not prior knowledge. A low faithfulness score means the response contains much information invented by LLM. The score depends highly on the intrinsic quality of LLM and prompt engineering. In practice, one can try prompts like “Answer the question based on the given context but not the priori knowledge” or ask LLM to provide its thoughts when generating a response to increase the faithfulness score.
Completeness.
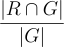
Completeness compares the generated response with the ground truth one to measure if all points in the ground truth are addressed by the generated response. If this score is low, one should first check if IR recall is good enough, as it is the upper bound. Then one can check the IR precision to see whether the LLM is misled by irrelevant information. Finally, one may need to investigate every test query in the ‘golden dataset’ and adjust prompts to increase the completeness of the generated response.
Relevance.
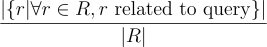
The relevance metric leverages the generated answer and the user’s input query, measuring whether the response is off-topic. A high relevance means the generated response sticks to the query, but not necessarily that the response is correct. To improve output relevance, similar to completeness, one should first ensure the good performance of the IR and then do prompt engineering by investigating test queries case by case.
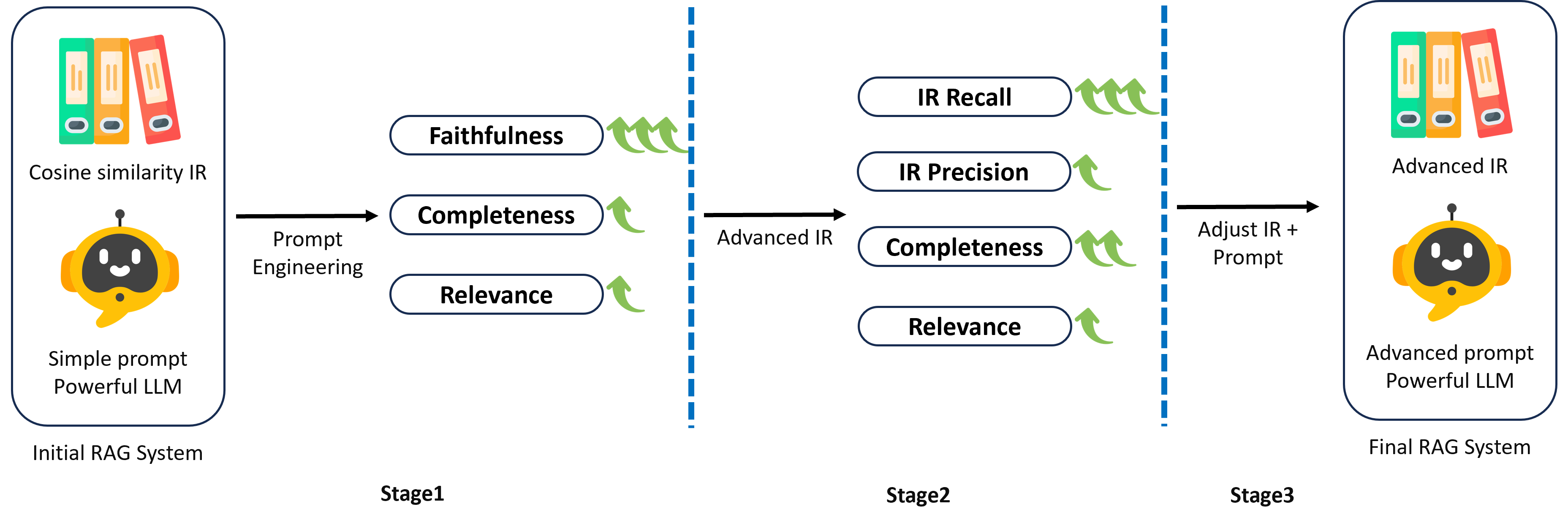
Based on the defined metrics, we propose a 3-stage evolution schema to help people build their pipeline efficiently. Starting with an initial RAG system with a cosine similarity IR, a simple prompt, and a powerful LLM, Stage 1 focuses on the faithfulness metric by leveraging prompt engineering. By experimenting with prompts in this stage, one can gain insights into the used LLM and become more familiar with the dataset. Techniques like few-shot prompting with examples and chain of thoughts or ReAct are good candidates to try. After this stage, one can develop a RAG system that provides answers based on the context of IR output with fewer hallucinations.
Stage 2 emphasizes the IR Recall metric and completeness by improving the IR system. One can experiment with using a cross-encoder for IR or a better embedding module.
Stage 3 concentrates on fine-grained adjustments, such as increasing IR precision to reduce the tokens in prompts or adding instructions to shorten the length of generated responses. It is not necessary to increase all scores in this stage; instead, one should adapt the objective according to their specific use case.
Comparing Existing Solutions
We have proposed 5 essential metrics to include in model evaluation and their mathematical formulation. However, computing these metrics is not straightforward as the output of generative AI varies and is not as deterministic as in classical classification tasks. In this section, we will compare several existing solutions and examine how they compute the metrics we have defined. Generally, there are two ways to compute these metrics: the generative AI-based approach and the classification model-based approach.
![]()
RAGAS is an example of using LLM to evaluate the quality of a RAG system. The evaluation process utilizes LLM for tasks such as decomposition, reformulation, or classification. The following table illustrates the correspondence between our metrics and the metrics used in RAGAS.
| Our Eval Metrics | RAGAS |
|---|---|
| IR Recall | Context Recall |
| IR Precision | Context Precision |
| Faithfulness | Faithfulness |
| Completeness | Answer Correctness /Answer semantic similarity |
| Relevance | Answer Relevance |
For metrics such as Context Recall, Context Precision, Faithfulness, and Answer Correctness, part of the evaluation process involves using LLM to break down texts (input, output, context, etc.) into sets of statements and then using LLM to identify the degree of overlap between these sets. The metric Answer Relevance is calculated by generating several questions based on the answer and then computing the cosine similarity between the generated questions and the user’s input query. As for Answer Semantic Similarity, it is computed by a cross-encoder instead of using an LLM. For more details on these metrics, please refer to the RAGAS documentation .
| type of context/response | context_recall | context_precision | faithfulness | answer_correctness | answer_relevancy |
|---|---|---|---|---|---|
| ground_truth | 0.91 | 0.83 | 0.91 | 0.99 | 0.93 |
| noisy_context (post) | 1.0 | 0.83 | 0.92 | 0.99 | 0.92 |
| noisy_context (pre) | 1.0 | 0.52 | 0.94 | 0.99 | 0.96 |
| wrong_context | 0.16 | 0.16 | 0.22 | 1.0 | 0.97 |
| short_answer | 0.91 | 0.83 | 0.95 | 0.90 | 0.88 |
| redundant_answer | 0.91 | 0.83 | 0.61 | 0.73 | 0.91 |
| hallucinate_answer | 0.93 | 0.83 | 0.12 | 0.25 | 0.74 |
| irrelevant_answer | 0.91 | 0.83 | 0.05 | 0.20 | 0.68 |
The table above presents an experiment we conducted using a toy dataset. Initially, we manually constructed a ground truth dataset with precise and accurate context and responses. We then modified the context and responses to introduce noise and incorrect information.
We introduced two types of context errors:
- noisy_context: the ground truth context with redundant, irrelevant information. In “noisy_context (post),” the irrelevant information comes after the ground truth context, while in “noisy_context (pre),” the irrelevant information is placed before the ground truth context.
- wrong_context: only irrelevant information.
We also introduced three types of response errors:
- redundant_answer: ground truth with additional irrelevant information.
- hallucinate_answer: answers related to the query but not present in the context.
- irrelevant_answer: answers that are unrelated to the query.
Additionally, we included a short_answer, which is a short version of the ground truth answer. For example
{
"query": "Who is the current CEO of OpenAI?",
"answer": "the current CEO of OpenAI is Sam Altman",
"short_answer": "Sam Altman"
}
Overall, RAGAS is capable of detecting various issues within a RAG system and pinpointing its bottlenecks. For instance, when adding noise to the context (noisy_context), we observe that the context recall remains nearly the same while precision decreases. Additionally, when using completely incorrect context (wrong_context), both context recall and precision are very low. Furthermore, when the answer contains redundant, hallucinated, or irrelevant information, the faithfulness score is low.
| ind | context_recall | context_precision | faithfulness | answer_correctness | answer_relevancy |
|---|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 1.00 | 0.96 | 0.92 |
| 1 | 1.0 | 1.0 | 1.00 | 0.96 | 0.94 |
| 2 | 1.0 | 0.0 | 1.00 | 0.64 | 0.93 |
| 3 | 1.0 | 1.0 | 1.00 | 0.98 | 0.88 |
| 4 | 1.0 | 1.0 | 1.00 | 0.97 | 0.79 |
| 5 | 0.5 | 1.0 | 0.75 | 0.89 | 0.84 |
However, RAGAS is not suitable for tracking the performance evolution of specific examples. As illustrated in the above table, context recall, context precision, and faithfulness are not sensitive to minor changes, as their values are highly quantized (taking values only in {0,1} for example).
Pros:
- Fine-grained metrics make it easy to identify the system’s bottlenecks.
- Open-source project, easy to personalize and extend.
Cons:
- LLM evaluation is slow, very slow.
- Some scores are quantized and unable to capture small changes in the pipeline.
![]()
Deepchecks is an example of using a classification model for LLM evaluation. Basically, most of their metrics are computed using a cross-encoder. The following table illustrates the correspondence between our metrics and the metrics used in Deepchecks.
It is worth noticing that in Deepchecks’ new version v0.8.0, they have also integrated some LLM-based metrics and made it possible to use personalized prompt templates to add new metrics. Their predefined LLM metrics include Correctness, Completeness, and Document Relevancy. However, there is currently no further information about how these metrics are computed. We inferred a guess based on the names of these LLM-based metrics.
| Our Eval Metrics | Deepchecks |
|---|---|
| IR Recall | Retrieval Relevance / Document Relevancy (LLM) |
| IR Precision | Retrieval Relevance / Document Relevancy (LLM) |
| Faithfulness | Grounded in Context / Correctness (LLM) |
| Completeness | Relevance / Completeness (LLM) |
| Relevance | Relevance / Relevance |
It is important to note that the RAG system quality metrics in Deepchecks are not as fine-grained as those in RAGAS or our proposition. However, they do offer more linguistic metrics such as Reading Ease, Formality, or Fluency. Additionally, the product provides an intuitive interface that makes it easy to navigate through the examples in your dataset. Furthermore, since it also supports personalized metrics, users can easily add RAGAS metrics to their dashboard.
The following figure illustrates the interface of Deepchecks.
Regarding the metrics, we obtain a low score for document relevancy when the context is noisy or incorrect. It is reassuring to see that the redundant information in noisy context does not impact the “grounded in context” metric. For redundant, hallucinated, and irrelevant answers, all of them receive a low score in the “grounded in context” metric. However, it is not clear what correctness and completeness refer to. It is worth noting that Deepchecks does not use the ground truth response to compute these metrics.
| type of context/response | correctness | completeness | document relevancy | relevance | grounded in context |
|---|---|---|---|---|---|
| ground_truth | 4.83 | 5 | 5 | 0.98 | 0.53 |
| noisy_context_post | 4.83 | 5 | 3.17 | 0.98 | 0.52 |
| noisy_context_prev | 4.67 | 5 | 2.83 | 0.98 | 0.52 |
| wrong_context | 3.67 | 5 | 2.17 | 0.98 | 0.24 |
| short_answer | 5 | 4.67 | 5 | 0.41 | 0.69 |
| redundant_answer | 4.83 | 4.67 | 5 | 0.99 | 0.32 |
| hallucinate_answer | 4.33 | 5 | 5 | 0.99 | 0.17 |
| irrelevant_answer | 2 | 1.33 | 5 | 0.26 | 0.04 |
Pros:
- Fast evaluation.
- User-friendly interface
Cons:
- Predefined metrics are not rich enough.
- Paid service.
Conclusion
Evaluation is a crucial part of the development of the RAG system. A permanent evaluation process necessitates a careful choice of metrics and the construction of a representative dataset. Based on our experience, in this article, we highlight 5 essential metrics that should be included in the evaluation process, provide a guideline for dataset construction, and introduce a 3-stage evolution schema to help people build their pipeline in an efficient way. Through sharing our experience, we hope to help people transform towards a metric-driven development of a RAG system.