
Invisible code and XSS attacks
 Sylvain Pollet-Villard
Sylvain Pollet-Villard- 11 Min To Read
- 19 Jul, 2023
Trojan: Attacks from the inside
XSS attacks were quite common at the time of the early web. They were used to steal cookies, to redirect users to malicious websites, to inject malicious code in the page, etc. Websites were more vulnerable to XSS at that time because they used a lot server-side templating with technologies like PHP or JSP, with very few built-in protections for injecting JavaScript code into HTML responses. Today, we are much more careful about escaping user inputs and evaluating HTML dynamically. We use frameworks like React or Vue.js to build our web applications, which are based on declarative templating that escape all HTML by default and encourage sending serialized data instead of HTML on the wire. Dynamic code evaluation is considered a bad practice and injection patterns are catched by code analysis tools like ESLint or SonarQube. XSS attacks have therefore to find more creative ways to inject malicious code into the page. If they can’t inject from the outside, they will try to inject from the inside, targeting the code of the application itself. They can do that directly through project dependencies or pull requests to open source projects, or indirectly through StackOverflow answers, blog posts, AI chatbots, etc.
Now, pushing malicious code in the daylight in front of the eyes of a development team is not easy. Even with the best obfuscation techniques, it’s still easy to spot a code that does more than what it is supposed to. This means attackers have to find a way to hide their intentions. In this article, we are going to explain one technique to do so: Unicode invisible characters.
Invisible characters in Unicode
Unicode , since UTF-8, has invisible zero-width characters. Of course they are not designed to be invisible, it’s more a consequence of the way some characters are badly used. These characters are called Variation Selectors . The idea of Variation Selectors was to be able to get a variant of the glyph of the previous character. For example, you can take the umbrella glyph and add a variation selector to get the emoji version of this glyph.
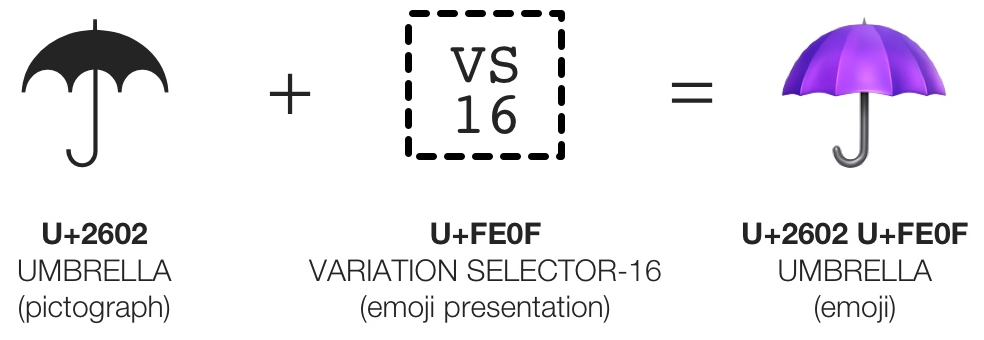
If you use a variation selector on a character that is not supposed to have a variant, for example another variation selector, the specification states that these characters should be ignored, and therefore not displayed on the screen. Some code editors displayed them as rectangle characters, but if they want to strictly respect the Unicode standard, they should not display them at all. Typically, on a web browser, such characters are not displayed, but they are still present in the source code. This is where it starts to be dangerous, because developers may pick some code from StackOverflow and copy/paste it in their application, or accept a pull request read on Github.com. If the code contains invisible characters, they will be copied too, and the code will be executed in the application.
How to use invisible characters in JavaScript
In UTF-8, we have 16 Variation selectors, in the block range FE00-FE0F. This gives us 256 possible pairs of variation selectors, which can be used to store 1 byte of information in 2 characters (4 bytes).
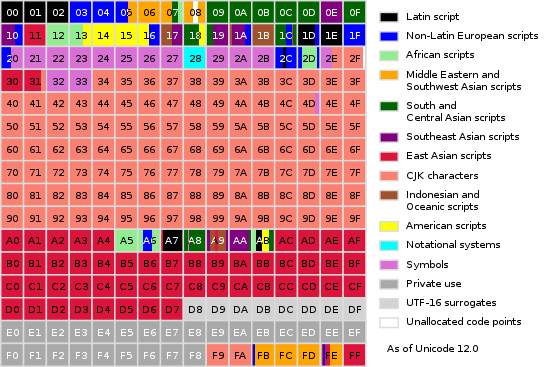
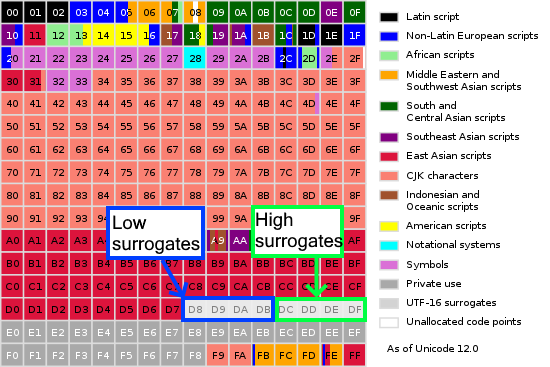
With the UTF-16 specification, we have more room for that: UTF-16 brought the concept of surrogates, a range of characters that can be combined as a pair to represent a single character. Such pairs are composed of a High Surrogate (D800-DBFF) and a Low Surrogate (DC00-DFFF). This technique enabled the introduction of very large new blocks of Unicode characters. Most of them are not being used yet, and reserved for future evolutions of the standard. One of these blocks is the Variation Selectors Supplement, between E0100-E01EF (240 characters on 8 bytes). This gives us 57600 new possible pairs of variation selectors, which can be used to hide 5 bytes of information in 32 bytes of UTF-16 invisible characters. The ratio looks less interesting than UTF-8 but the total number of Unicode characters required to store a secret is 5x lower. This may do the difference to prevent invisible code being spotted by a developer looking at the number of characters changed in a commit or in a cursor selection.
Of course, these invisible characters cannot be used as-is. We need another injection point to decode these invisible characters into proper JavaScript malicious code that will be evaluated. The most common injection point is the eval function. But it can also be the Function constructor, or any other function that evaluates a string as JavaScript code.
An example of Injection Code
The aim of the attackers is to make this injection point look as innocuous as possible, and they compete in imagination for that. For the needs of this article, I’m going to present a made-up example of such an attack, simple enough to be able to explain it in this article, but vicious enough to demonstrate the pernicious nature that these attacks can take:
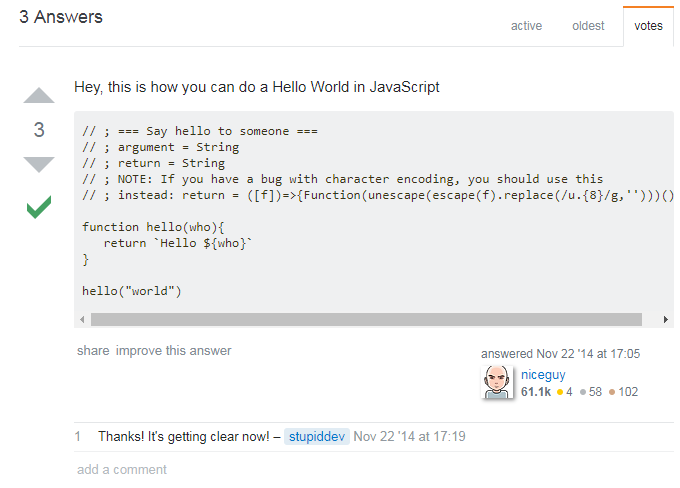
Let’s take the example of a StackOverflow answer. The question may be general enough to bring a lot of attention, and the answer may be very well written, with a lot of upvotes from fake accounts. The answer may contain a code snippet that looks like a very good solution to the problem. But in fact, it also contains the malicious code hidden in invisible characters.
StackOverflow has syntax highlighting but it is still optional. It’s up to the poster to set the language of the piece of code to enable it. The attacker can use this to dissimulate the injection point in a fake comment. If we copy the code in an editor with syntax highlighting, you see this:
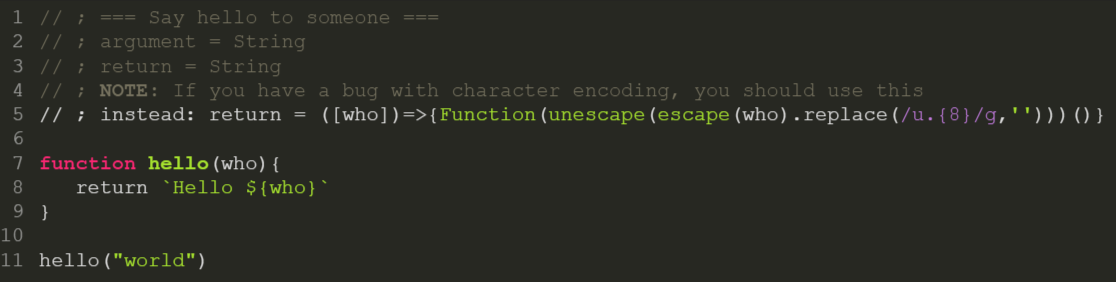
It appears that the last line was not a comment. The trick is to insert an invisible zero-width character between the two slashes ; then it is no longer a line comment, but a literal for a regular expression:

Now we can execute malicious code on this line, but we also need to end this instruction starting with the RegExp. Here we simply used a semicolon, disguised as presentation, to separate the two instructions. But we had many other imaginative ways to do that:

Note the last one, using the divide operator between the regexp and the result of the following expression: because you now have two consecutive slashes, the one that ends the regexp and the other that is used as divide operator, this is enough to trick many syntax highlighters into thinking that this is a line comment. So only the first slash will be displayed in white, which can be interpreted as a minor bug by some developers and not arouse suspicion.
The following parts of this fake line comment are tricks to avoid attracting too much attention. The instead: part that follows may look like this is the continuity of the comment of the previous line, but it will be interpreted here as a label in JavaScript, a not-so-known feature of the language.
Then you have what looks like an assignment to return. Most JS developers know that return is a reserved keyword and cannot be assigned to, so would interpret this as a note from the author to replace the return value with the following part in case you have a “bug with character encoding”. This part is vague enough and plausible enough to convince the developer to not remove this comment, in case they might need it in the future. At this point, the developer should be convinced this is a harmless comment.
The trick is that this return is not the return you all know. It uses the cyryllic “е” which is indinstinguishable from the Latin One in almost all existing fonts. This is due to how Unicode regroup the different alphabets, you end up with some duplicates that use the exact same glyphs but have different codepoints. But different code points means a different JS variable identifier: this special cyrillic return is no longer a reserved keyword but a valid variable name. And because you can declare global variables in JavaScript without the var keyword, this is a valid instruction that will be executed and will assign the following function to a global variable.
The malicious code and execution point
Now that our injection code is set up, the following part is the actual malicious code, which will be executed when the return function is called. This is the execution point.
In this example, the execution point is really close to the injection point. The same fake return is used inside our hello function. It looks like a simple return statement that returns a string, but it is in fact a function call. The return function is called as a tagged template literal, another little known JS feature, with a parameter that is a string containing the malicious code. This is the actual payload that will be executed. When faking keywords like return, this kind of function call is very hard to notice even for experienced JS developers.
But where is the malicious code, you might ask? Hidden as invisible characters, of course! The function code assigned to our fake return may bring your attention: it is using the Function constructor as a dynamic code evaluation pattern. And the code that is dynamically evaluated is the result of a transformation of the string received as function parameter. This transformation first escapes the string to replace invisible characters by their Unicode code point notation (for example, %u200b for the zero-width space). Then it replaces the 8 following characters after %u with an empty string, in order to shift the invisible alphabet to classic ASCII. For example, %uDB40%uDD61 will be replaced by %u61 which is letter a in Latin alphabet.
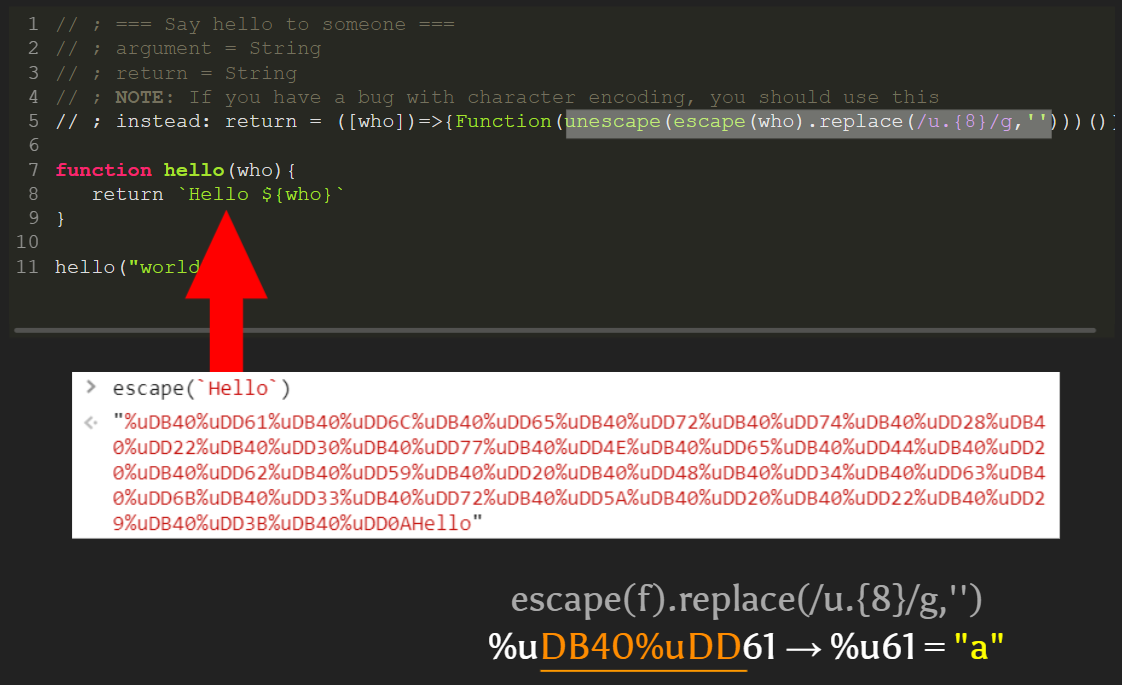
This is not the most effective way to decode invisible characters, but it is the shortest one. The total size of the invisible code does not really matter compared to the size of the visible injection point: it does not matter if the dev spots 500 hidden characters or 50000, the goal is to not be spotted at all.
Finally it unescapes the string to replace the list of encoded Unicode codepoints back into the actual malicious code, and then it executes it through Function("code")().

Fortunately, the attack was not very serious. We may not have the same luck next time!
The danger of these attacks
The attack I just described is not the only one possible, and it is not the most sophisticated one. It is just a simple example to illustrate the technique. But it is a real threat, and it is not easy to protect against every possible attack.
The danger of this kind of attack is that it’s an attack from the inside, like a trojan horse , and this type of attacks is not the priority of most security tooling. These attacks can target a very wide range of victims (like a StackOverflow newbie question) and exploit the target through their lack of knowledge in the language and the bad tooling they use.
Another danger is that the execution point, the injection point and the malicious payload are separated. This means it can be added to a codebase in multiple commits, by multiple people, and it can be done in a way that is not obvious to spot. We may find out that public codebases have some dormant injection functions or malicious code that waits for the next step to be triggered.
Also remember than real attacks are often much more complex, intricate and vicious than the simple example above. It can be combined with social hacking or online surveillance when attacking precise targets. Finally, it can happen not only in your codebase, but in the code of any of your dependencies.
How to protect against this
The first thing you can do is to configure your code editor to alert you when your code contains invisible characters. On modern IDE, such as the latest version of VSCode, this is now enabled by default, but you should double-check if the setting is enabled:
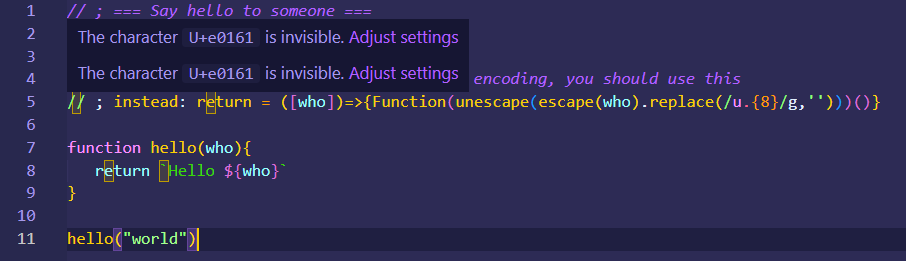
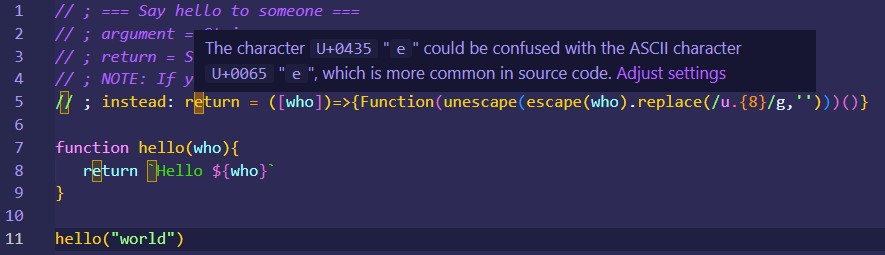
The second thing you can do is to configure your linter to detect such suspicious code in your CI build script. Unfortunately, the packages I found when looking for “invisible characters detectors” tend to miss some patterns of invisible code. So I recommend you write your own rules and double-check everything.
Code reviews, dependency updates and audits are always a good idea to manage the risk. Dedicated training for security issues awareness are also a must-have. You cannot mitigate a risk if you do not know the risk exists.
Finally, this should be another lesson to stop copy-pasting code from StackOverflow without understanding it. This is a very common practice, and it is a very bad one. You should always read and understand the code you copy-paste, or even better, not copy-pasting but writing it by yourself with your specific context and your specific needs. This is the only way to be sure that you are not introducing any security risk in your codebase.
Conclusion
Application security covers many different aspects. While security at runtime is the most visible and the most talked about, it is not the only one. Security at build time is also important, and it is often overlooked. Many sneaky and little-know techniques can be exploited, and invisible code is one of them. It is for me a very symbolic example of a larger problem. I hope this article will help you to be more aware of this risk and to protect yourself against it.